Engine Diagrams Online
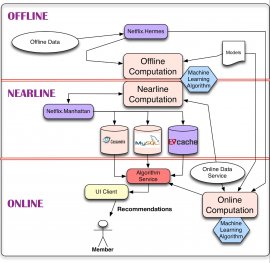 The simplest thing we are able to do with information is to store it for later on traditional handling, leading to area of the design for handling Offline tasks. However, calculation can be achieved offline, nearline, or on line. Online computation can respond better to recent activities and individual relationship, but has to respond to requests in real time. This could easily reduce computational complexity for the formulas utilized plus the quantity of data that may be prepared. Offline calculation features less restrictions on the level of information and the computational complexity of the algorithms because it works in a batch manner with relaxed time demands. But can very quickly develop stale between changes because latest information is perhaps not incorporated. One of the key problems in a personalization architecture is how exactly to combine and manage on the internet and traditional computation in a seamless manner. Nearline computation is an intermediate compromise between those two settings in which we can perform online-like computations, but do not require all of them is supported in real time. Model education is yet another form of calculation that utilizes current data to build a model which will later on be properly used throughout the actual computation of results. Another an element of the structure describes the way the different kinds of occasions and information need to be managed by the occasion and information Distribution system. A related problem is simple tips to combine the different indicators and designs that are required over the traditional, nearline, and online regimes. Eventually, we must also work out how to combine intermediate advice causes a means that produces sense when it comes to individual. The remainder with this post will detail these aspects of this design including their particular communications. To carry out so, we will break the overall drawing into different sub-systems and we will go in to the details of each of them. As you read on, it's really worth keeping in mind which our entire infrastructure runs across the general public Amazon Web providers cloud.
The simplest thing we are able to do with information is to store it for later on traditional handling, leading to area of the design for handling Offline tasks. However, calculation can be achieved offline, nearline, or on line. Online computation can respond better to recent activities and individual relationship, but has to respond to requests in real time. This could easily reduce computational complexity for the formulas utilized plus the quantity of data that may be prepared. Offline calculation features less restrictions on the level of information and the computational complexity of the algorithms because it works in a batch manner with relaxed time demands. But can very quickly develop stale between changes because latest information is perhaps not incorporated. One of the key problems in a personalization architecture is how exactly to combine and manage on the internet and traditional computation in a seamless manner. Nearline computation is an intermediate compromise between those two settings in which we can perform online-like computations, but do not require all of them is supported in real time. Model education is yet another form of calculation that utilizes current data to build a model which will later on be properly used throughout the actual computation of results. Another an element of the structure describes the way the different kinds of occasions and information need to be managed by the occasion and information Distribution system. A related problem is simple tips to combine the different indicators and designs that are required over the traditional, nearline, and online regimes. Eventually, we must also work out how to combine intermediate advice causes a means that produces sense when it comes to individual. The remainder with this post will detail these aspects of this design including their particular communications. To carry out so, we will break the overall drawing into different sub-systems and we will go in to the details of each of them. As you read on, it's really worth keeping in mind which our entire infrastructure runs across the general public Amazon Web providers cloud.
Offline, Nearline, and on the web Computation
As stated earlier, our algorithmic results are calculated either online in real time, traditional in batch, or nearline in-between. Each method has its own pros and cons, which have to be considered for each use instance.On the web calculation can react quickly to occasions and make use of the newest data. An example will be construct a gallery of action films sorted for the member with the present context. Online elements are at the mercy of a supply and response time Service Level Agreements (SLA) that specifies the utmost latency of procedure in answering needs from customer applications while our user is awaiting guidelines to show up. This may make it more difficult to suit complex and computationally expensive formulas in this strategy. Additionally, a purely on the web computation may are not able to satisfy its SLA in certain situations, it is therefore constantly important to think about an easy fallback process such reverting to a precomputed outcome. Processing on line does mean that numerous data sources involved must also be around online, that may need additional infrastructure.
On the other side end for the range, offline calculation enables more alternatives in algorithmic strategy including complex formulas much less limitations on level of data that is used. A trivial example might be to periodically aggregate data from scores of film perform events to compile standard appeal metrics for guidelines. Offline systems likewise have simpler manufacturing requirements. Including, relaxed response time SLAs imposed by clients can be easily met. Brand new formulas can be implemented in production without the necessity to put an excessive amount of energy into overall performance tuning. This freedom aids agile innovation. At Netflix we make the most of this to support fast experimentation: if a unique experimental algorithm is slower to execute, we are able to choose to merely deploy more Amazon EC2 circumstances to ultimately achieve the throughput needed to run the research, in the place of investing important engineering time enhancing performance for an algorithm that'll show to be of little company value. However, because traditional processing won't have powerful latency demands, it does not respond quickly to changes in framework or brand-new data. Fundamentally, this could easily result in staleness that'll break down the user experience. Offline computation also needs having infrastructure for storing, processing, and opening large units of precomputed results.
Nearline computation is visible as a compromise between your two previous settings. In this case, calculation is carried out the same as within the on the web situation. However, we remove the necessity to offer results when they have been computed and certainly will instead keep all of them, letting it be asynchronous. The nearline calculation is done in response to user events so that the system can be more responsive between requests. This starts the entranceway for possibly more complicated processing to be done per occasion. An illustration will be update suggestions to reflect that a film has been seen just after a member begins to watch it. Outcomes could be stored in an intermediate caching or storage back-end. Nearline calculation normally a normal environment for applying progressive discovering formulas.
Regardless, the selection of online/nearline/offline handling just isn't an either/or question. All methods can and really should be combined. There are many how to combine all of them. We mentioned previously the idea of making use of offline computation as a fallback. An alternative choice should precompute part of an effect with an offline process and leave the less costly or even more context-sensitive elements of the algorithms for on line computation.
Even modeling part can be done in a crossbreed offline/online fashion. It is not an all-natural fit for conventional monitored category programs where in fact the classifier needs to train in batch from labeled data and certainly will only be used on the web to classify brand-new inputs. However, approaches such as Matrix Factorization are a far more normal fit for hybrid online/offline modeling: some factors could be precomputed traditional although some is updated in real time to produce a more fresh result. Other unsupervised approaches such as for example clustering also allow for offline computation associated with the cluster centers and web assignment of groups. These examples point out the alternative of isolating our model training into a large-scale and potentially complex international design training in the one hand and a lighter user-specific design education or updating period that can be performed online.
 Offline Jobs
Offline Jobs
Much regarding the calculation we have to do when working customization device discovering algorithms can be done traditional. This means that the jobs could be scheduled to-be executed periodically and their particular execution doesn't need to-be synchronous using the demand or presentation associated with results. There are two main primary types of tasks that fall in this category: design training and batch computation of intermediate or final results. When you look at the design training tasks, we gather relevant existing information thereby applying a machine discovering algorithm creates some design variables (which we'll henceforth make reference to due to the fact design). This design will most likely be encoded and stored in a file for later usage. Although the majority of the designs are trained offline in group mode, we supply some internet based learning practices in which incremental instruction is definitely carried out on line. Batch calculation of outcomes is the offline calculation process defined above by which we make use of present models and corresponding feedback information to calculate results which will be utilized at another time either for subsequent on line processing or direct presentation towards user.
Both these tasks need processed data to procedure, which usually is generated by operating a database query. Since these inquiries go beyond considerable amounts of information, it could be useful to run them in a distributed style, helping to make all of them great prospects for operating on Hadoop via either Hive or Pig jobs. After the queries have completed, we truly need a mechanism for publishing the resulting information. We a few demands for that procedure: First, it will inform members when the result of a query is prepared. Second, it will support various repositories (not merely HDFS, and S3 or Cassandra, for instance). Finally, it will transparently manage errors, allow for monitoring, and alerting. At Netflix we utilize an interior device called Hermes that provides most of these capabilities and integrates all of them into a coherent publish-subscribe framework. It permits information to-be delivered to customers in almost real time. In a few feeling, it addresses a few of the exact same usage situations as Apache Kafka, but it is maybe not a message/event waiting line system.
Indicators & Models
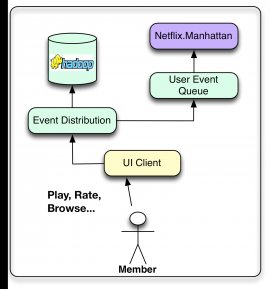
Regardless of whether we're doing an online or offline computation, we have to think of exactly how an algorithm will deal with three kinds of inputs: designs, information, and indicators. Designs usually are small files of variables that have been previously trained offline. Information is previously prepared information that has been kept in some form of database, including film metadata or appeal. We utilize the term "indicators" to mention to fresh information we feedback to formulas. This information is gotten from real time services and will be produced of user-related information, such as for instance just what the user has actually viewed recently, or framework information such as for example program, unit, time, or time.Event & information Distribution
Our goal will be change user connection data into ideas which can be used to improve the member's experience. For that reason, we would like various Netflix interface programs (Smart TVs, pills, online game systems, etc.) not to just provide a wonderful user experience but additionally gather as much user occasions as you can. These activities could be related to clicks, searching, viewing, as well as the content of the viewport whenever you want. Occasions may then be aggregated to supply base data for the formulas. Right here we make an effort to make a distinction between data and events, even though the boundary is obviously blurry. We consider activities as tiny units of time-sensitive information that have to be prepared utilizing the the very least number of latency possible. These occasions tend to be routed to trigger a subsequent activity or procedure, such as updating a nearline result set. However, we think about information much more heavy information devices that may should be processed and kept for later on usage. Right here the latency is not as essential as information high quality and amount. Obviously, there are user events which can be treated as both events and data and as a consequence delivered to both flows.At Netflix, our near-real-time event circulation is handled through an inside framework known as Manhattan. New york is a distributed calculation system this is certainly central to our algorithmic design for recommendation. It really is notably similar to Twitter's Storm, but it covers various concerns and responds to another collection of inner requirements. The info flow is managed mainly through signing through Chukwa to Hadoop the initial measures regarding the process. Later on we utilize Hermes as our publish-subscribe apparatus.
Recommendation Results
The goal of our machine learning method will be come up with tailored tips. These suggestion results is serviced directly from lists that individuals have previously calculated or they may be produced on fly by on the web algorithms. Definitely, we are able to consider making use of a mixture of both in which the bulk of the tips are computed traditional and then we increase freshness by post-processing the listings with on the web algorithms that use real time signals.At Netflix, we shop traditional and advanced results in various repositories becoming later eaten at request time: the primary data stores we use are Cassandra, EVCache, and MySQL. Each solution has advantages and disadvantages throughout the others. MySQL allows for storage space of structured relational information that would be required for some future procedure through general-purpose querying. However, the generality comes at cost of scalability issues in distributed conditions. Cassandra and EVCache both offer the advantages of key-value stores. Cassandra is a well-known and standard option whenever in need of a distributed and scalable no-SQL shop. Cassandra is very effective in a few circumstances, in instances when we require intensive and constant write operations we discover EVCache become an improved fit. One of the keys problem, but is not such where you can keep them on how to address what's needed in a manner that conflicting goals including query complexity, read/write latency, and transactional persistence meet at an optimal point for every single use case.
Share this article
Related Posts



Latest Posts